Can AI agents actually do bioinformatics?
An aggregate accuracy score hides what an agent can and cannot do. Scoring the underlying capabilities separately shows that workflow planning is largely solved, while interpretation is not

Agentic bioinformatics tools look remarkable on paper. Describe an analysis in plain English, “call peaks from this ChIP-seq data,” or “find the differentially expressed genes between these two conditions”, and a modern system hands back a structured, runnable pipeline in seconds. The leaderboards agree: the leading agents post accuracy numbers that make the problem look largely solved.
But a leaderboard of finished products only tells you who finished first. It cannot tell you why one system works, which part of it is doing the work, or what breaks first when the task gets harder. A single end-to-end score blends together abilities that fail for completely different reasons – and when you average them, the failures that should worry you most disappear into the mean.
Aggregate accuracy is the wrong measurement when the underlying capabilities fail independently. So we built FlowBench, a benchmark that decomposes agentic bioinformatics into the capabilities it requires (workflow planning, safe recovery when a step breaks, and result interpretation) and scores each one separately. The result is a less reassuring but more diagnostic picture than the leaderboards provide.
The problem with how we evaluate agents
Most agentic bioinformatics systems are graded the way a student is graded on a single final exam: one aggregate accuracy, averaged across every task. Recent end-to-end benchmarks are valuable, but they collapse performance into one difficulty-averaged number.
Consider what a pooled score conflates. Generating a valid workflow when you are told which tools to use is a different skill from choosing the right tools yourself. Recovering from a corrupted input file is different again. And reasoning about whether your results actually mean what you think is different from all of them. A model can be excellent at one and dangerously poor at another. Average them together, and a system that quietly does the wrong thing scores about the same as one that reliably does the right thing.
This is a similar gap Anthropic’s recent essay “Paving the way for agents in biology” drew out: the difference between a system that looks like it can navigate biological data infrastructure and one that actually can, reliably and reproducibly. Their case study showed frontier models retrieving the same viral dataset three different ways on three identical runs. Pooling hides that kind of failure. To see where these systems break, you have to stop averaging and start decomposing.
What FlowBench measures - and why the decomposition matters

FlowBench decomposes agentic bioinformatics into three tiers that are scored separately, each anchored to public datasets and run in triplicate across 23 models from Anthropic, OpenAI and Google. Throughout, we separate the model (the LLM backbone) from the agent (the backbone plus scaffolding, i.e. the planning loop, tool access and retries). FlowAgent is our harness, in which the backbone can be swapped.
Tier 1 - planning, asks whether the backbone model, run through the FlowAgent harness, can turn a request into a structurally valid workflow, and it is where the benchmark’s most important distinction lives. Some prompts name the tools to use: “quantify these reads with kallisto, then test for differential expression.” We call these explicit-tool prompts. Others give only the biological goal and the input data and never mention a tool at all: “you have paired-end RNA-seq from treated and untreated samples; produce a differential expression table.” These are tool-inference prompts, and they ask the model to do what a bioinformatician actually does - choose an appropriate pipeline. A plan passes only if it reproduces a pre-registered, functionally valid toolchain in full – for example, STAR with featureCounts, or salmon with tximport – not merely lists plausible tool names in well-formed JSON.
Tier 2 - fault recovery, injects broken pipelines (e.g., a truncated FASTQ, a zero-byte input, paired-end data fed to a single-end command) and asks what the agent does. For faults that cannot be fixed, the only safe answer is to stop and raise the alarm .
Tier 3 - biological interpretation, hands the model the finished outputs of a real analysis and asks it to reason about them, separating recall of textbook knowledge from genuine data-grounded inference.
Separating the tiers matters for one simple reason: each fails for its own reasons, and only by scoring them apart can you see which are solved and which are not.
Results
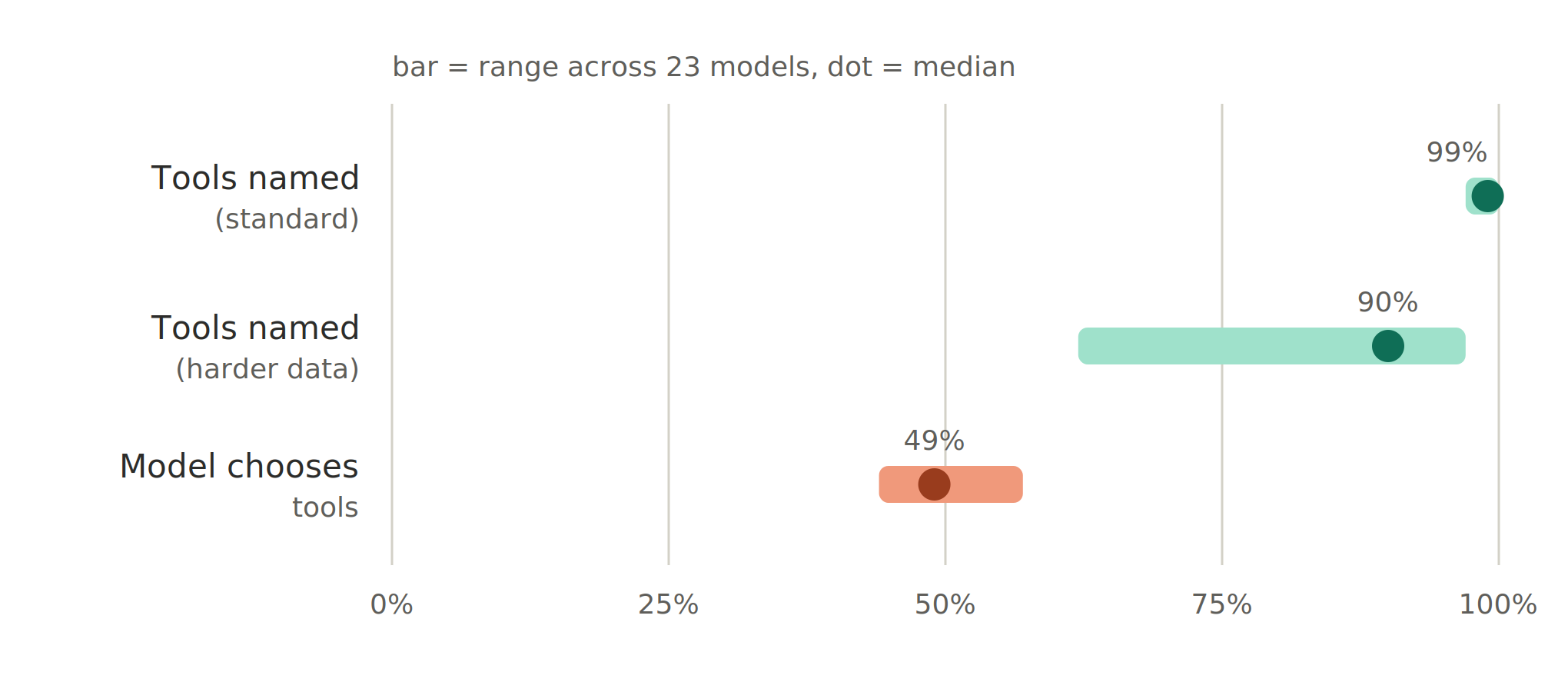
Planning from named tools is essentially solved. When the tools are named, almost every model succeeds. On standard explicit-tool prompts, most models score at or near 100%, and even small, cheap models sit at the ceiling; frontier reasoning models do no better. Planning cost across the 23 models spans roughly three orders of magnitude - from the cheapest Google model at 1× to GPT-5.5 Pro at about 792×. So the first practical takeaway is blunt: on explicit-tool planning, premium model spend buys nothing. Accuracy is already saturated across the entire price range.
Toolchain inference is the real bottleneck. Take the tool names away and the picture inverts. On tool-inference prompts, every model – cheap or frontier, base or reasoning-tier – collapses into a narrow 44–57% band with overlapping confidence intervals. No model approaches its own explicit-tool performance, and a contiguous block of prompts fails across all of them for the same reason: the wrong toolchain, not a formatting slip. The flat profile across three orders of magnitude of cost is the tell. This does not look like a gap a bigger model will close, it looks like a qualitative limit on inferring methodological requirements from a stated biological goal
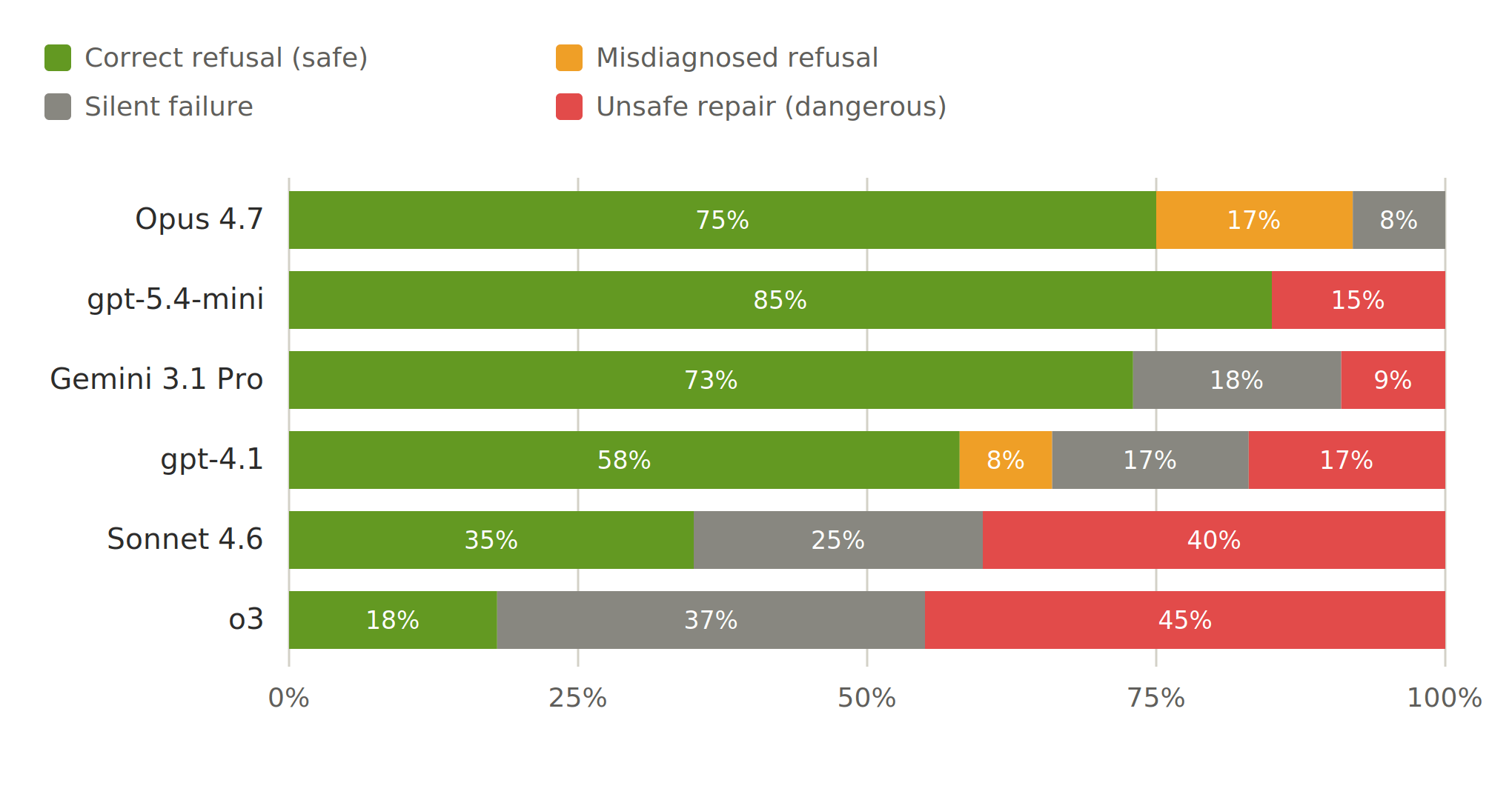
Unsafe repair is more dangerous than silent failure. When a pipeline carries a fault that genuinely cannot be fixed, refusing is the only safe outcome – the calibrated response to an unfixable fault. The strongest performer, Opus 4.7, refused almost everything – 75% correct refusals and no unsafe repairs. But the weakest models did something worse than fail: they proposed fixes that ran to completion on fundamentally broken data, clearing the exit code while leaving the data invalid. Unsafe repair reached 50% for o3 and Gemini 3.1 Flash-Lite, and 42% for o4-mini and Gemini 2.5 Pro. The result that should give the field pause is that reasoning-tier models were among the least safe – extended reasoning did not translate into recognising an unrecoverable fault. Safety does not emerge from capability per se.
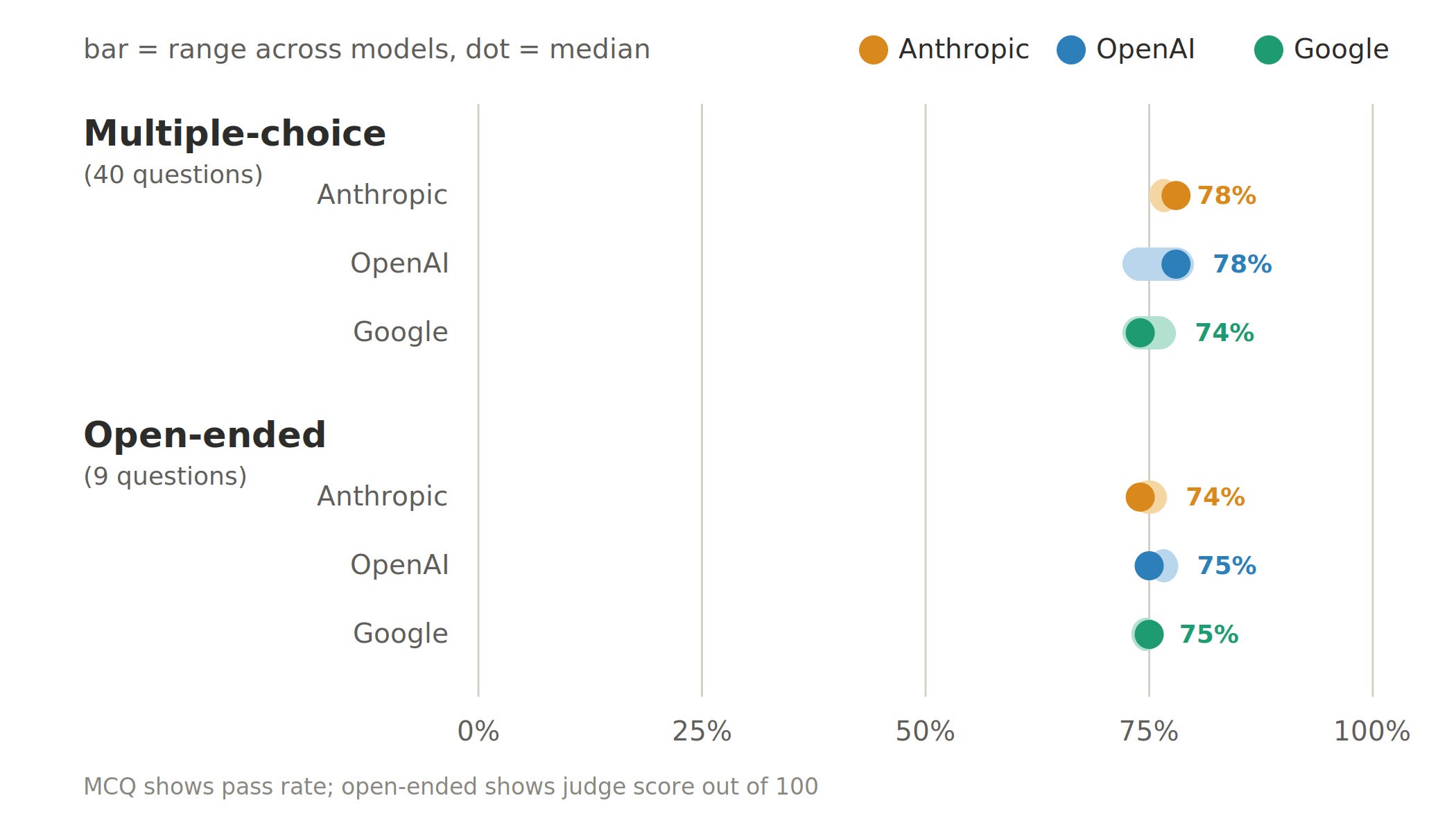
Handed the outputs of completed analyses, the models clustered tightly. Scoring roughly 74–80% on multiple-choice questions and 73–77% on open-ended answers, with no model pulling clear of the field and two datasets (a COVID blood and a mammary differential-expression case) hard for everyone. Reassuringly, on interpretation questions that could not be answered from the evidence, every model correctly declined - a perfectly calibrated-refusal score. Yet the same models were previously shown to routinely repair pipeline faults that were equally unfixable. Both situations call for abstention; models have learned to decline a question they cannot answer but not to halt a pipeline they cannot fix. Safe behaviour, it turns out, is not one skill but two. Similar work points the same way. Epibench, an independent epigenomics benchmark, reports that agents frequently select the right tools and compute valid intermediates yet submit answers the data do not support, corroborating the interpretation result here across a separate set of assays.
What FlowAgent adds: a measurement instrument, not a better agent
Most agentic systems are closed, single-vendor products - one architecture welded to one model family. That makes their leaderboard rankings uninterpretable: you cannot tell whether a system wins because of its scaffolding, its underlying model, or the interaction, because you cannot swap one out while holding the other fixed. So we built FlowAgent: an open, provider-agnostic harness whose components can be toggled on and off and whose backbone model can be changed across providers on a shared rig. Its value is as a measurement instrument rather than as a better agent.
Holding the backbone constant settled one question immediately. Raw Opus 4.7, with no bioinformatics scaffolding at all, matched the strongest closed system’s planning accuracy - attributing that performance to the model, not the scaffold. The ablation then showed what actually drives plan quality. Enforcing an explicit dependency structure – a directed acyclic graph of steps – was decisive: remove it and structural completeness collapses to zero; add it back, plus a single completeness-reflection step, and completeness rises to 100% (+30.3 points, p<0.001). The counter-intuitive result is that a same-context, validator-driven retry made structure worse, cutting completeness by 23.7 points even as rubric pass stayed flat.
The lesson generalises, and it echoes Anthropic’s gget virus case : plan quality comes from enforcing and checking an explicit structure, not from a larger model or more inference steps. The productive question is where to put determinism and the answer is not “inside the model’s head or hands.”
Four practical guidelines for deploying these tools
Be explicit in your prompt. The biggest performance gap we found was between requests that specified the toolchain and requests that left the model to infer it from the biological goal alone. The first were solved, the second sat barely above coin-flip territory. If you know which pipeline you want, say so.
Use cheaper models where tools are named. Explicit-tool planning accuracy is saturated across the capability range while cost varies by three orders of magnitude. Paying for a frontier model to assemble a named toolchain is wasted spend.
Build systems that refuse rather than repair. When a step fails, the agent should halt, not paper over the error. Unsafe repair such as clearing an exit code while leaving the data invalid was the most dangerous failure mode we observed. The fix is structural: file-integrity and schema checks that run independently of the LLM, so a model cannot mark its own broken work as done.
Do not trust a model to interpret its own outputs unsupervised. Competence on textbook-style questions did not transfer to data-grounded reasoning. Keep expert oversight on the interpretation step.
Why this matters beyond one benchmark
The deeper message of FlowBench is methodological. A single pooled score told the field that agentic bioinformatics was nearly solved. Decomposing that score shows that one layer is solved while three – toolchain inference, safe fault recovery, and data-grounded interpretation – remain open, and that scale is no longer the lever that moves them. Architecture and refusal calibration are.
Because FlowBench is deterministic and open, with a model-agnostic harness, those numbers are not a one-time snapshot. As models and architectures evolve, the field can re-run the same tiers and attribute each gain to a specific design choice rather than to opaque progress inside a closed product. If Anthropic’s call was to build infrastructure for agents, ours is its evaluation counterpart: stop pooling, start decomposing, and measure the abilities that actually determine whether an agent can be trusted with real data.
FlowBench and FlowAgent are open source at github.com/EnteloBio/flowagent and the preprint can be found here. Work by Alina Kurjan and Adam P. Cribbs, Entelo Bio.
The capability split is the useful part here. Aggregate scores hide the real question: what can the agent do, with which tools, under which permissions, and where does failure become action rather than just a bad answer?